IIIT-INDIC-HW-WORDS-Gujarati
Language
Gujarati
Modality
Handwritten
Details Description
To collect handwritten Gujarati word images, we use forms containing well separated boxes. Each form has 20-25 pairs of boxes. One box contains a reference word image and another box to write the shown word image in each pair. The writers (who can read and write the language) with different educational backgrounds and ages can write the shown words inside the white box. The writers are free to use pens of their choice and write the words in their natural style. There is no constraint to write except “write within the white box.” There are 17 writers (who can read and write Gujarati) to write the words. The collected pages are digitized using a flatbed scanner with a resolution of 600 DPI in color and stored in JPEG format. Using morphological operations, we can extract and label the handwritten word images. Through this procedure, we create this dataset having handwritten Gujarati word images and corresponding ground truth transcriptions. This dataset consists of 1,16,696 word images and their corresponding ground truth transcriptions. We divide this dataset into Training, Validation and Test Sets consisting of 82,563, 17,643, and 16,490 word images and their corresponding ground truth transcriptions, respectively. There are 10,963 unique Gujarati words in the training set.
Training Set:
train.zip contains folder named “images” with 82,563 word level images, “train_gt.txt” file containing image name and ground truth transcription separated by “Tab space”, and “vocabulary.txt” contains list of 10,963 unique words in the Training set.
Validation Set:
val.zip contains folder named “images” with 17,643 word level images, and “val_gt.txt” containing image name and ground truth text separated by “Tab space”.
Test Set:
test.zip contains folder named “images” with 16,490 word level images, and “test_gt.txt” containing image name and ground truth text separated by “Tab space”.
Sample Word Level Images from Training Set
| Image | Ground Truth |
|---|---|
 |
|
 |
|
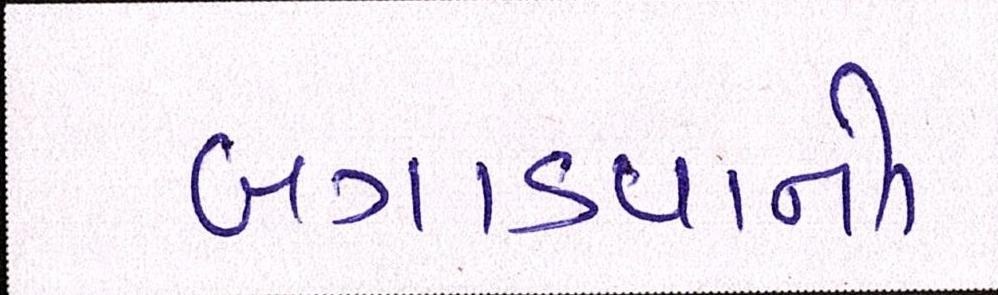 |
|
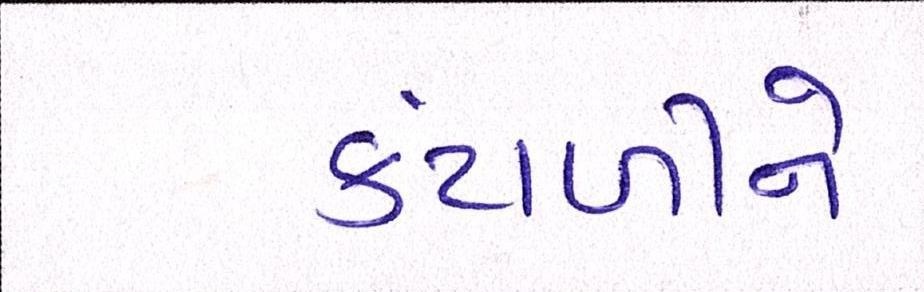 |
|
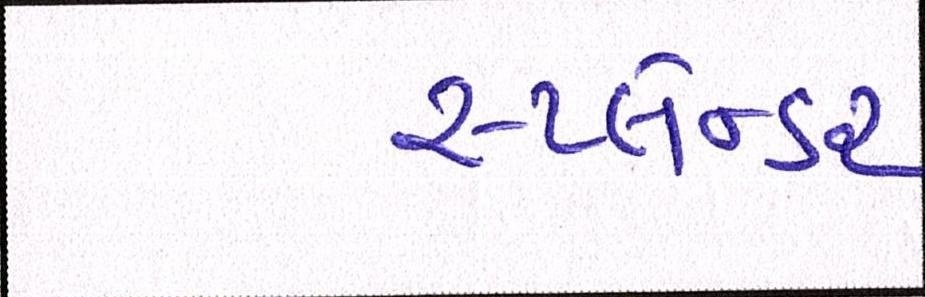 |
|
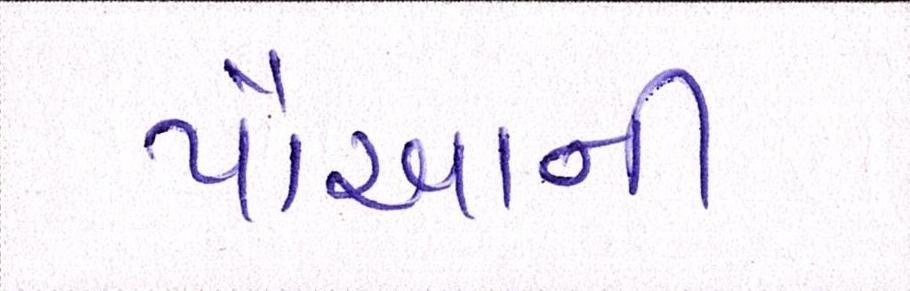 |
|
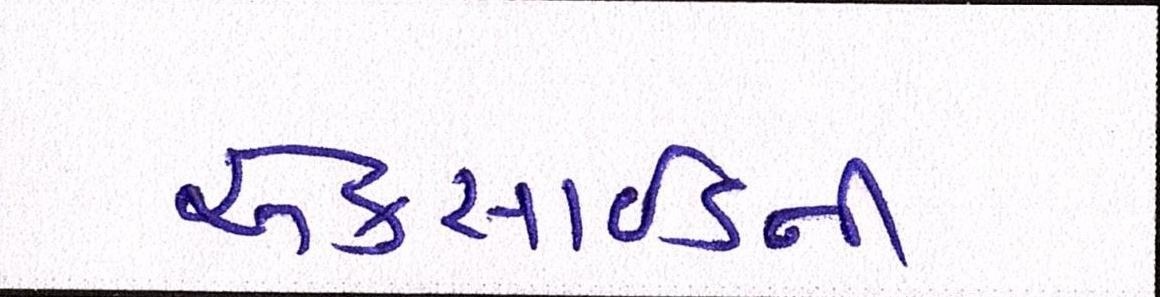 |
|
 |
|
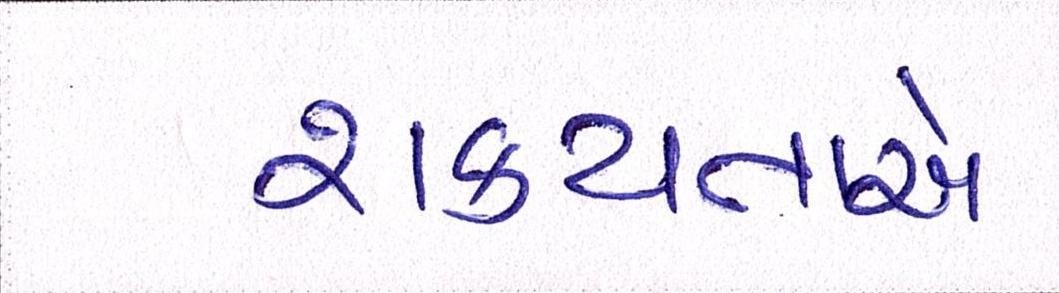 |
|
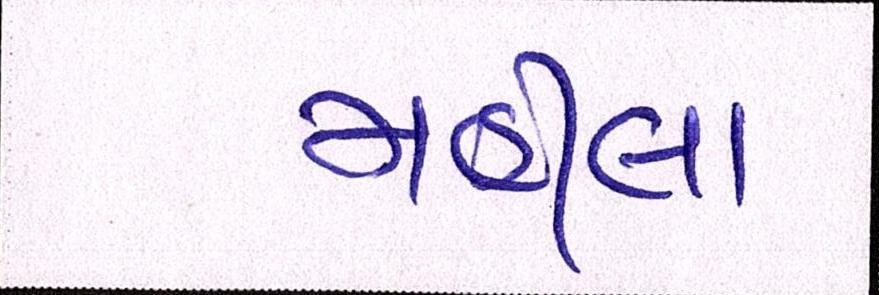 |
|
 |
|
 |
|
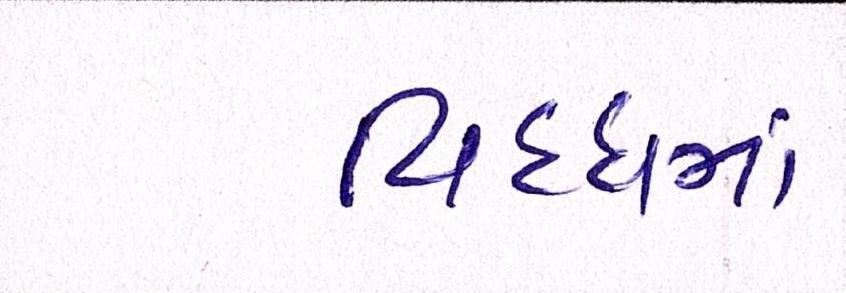 |
|
 |
|
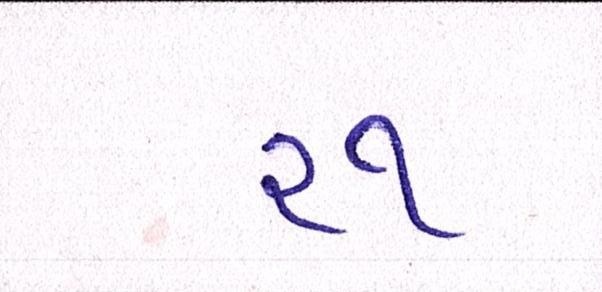 |
|
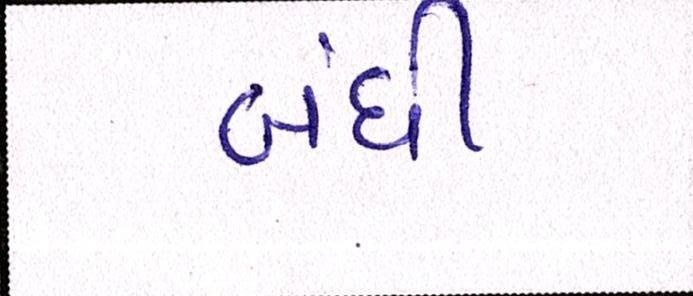 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
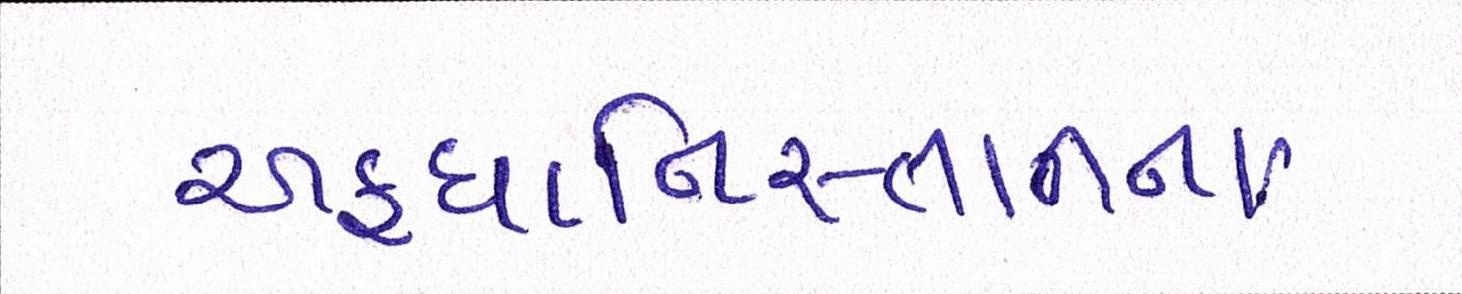 |
|
 |
|
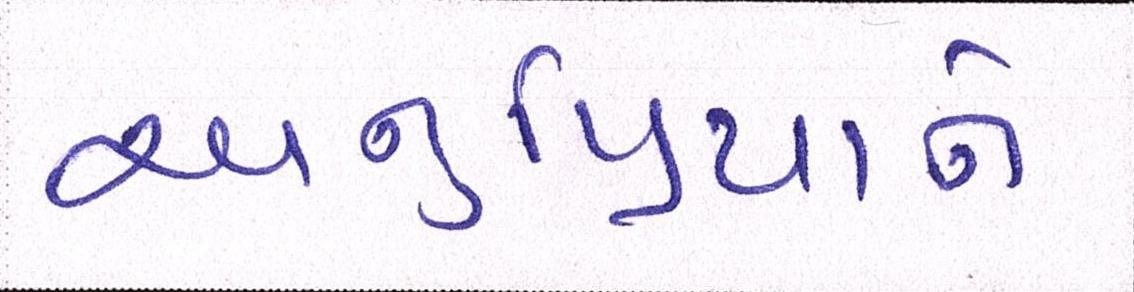 |
|
 |
|
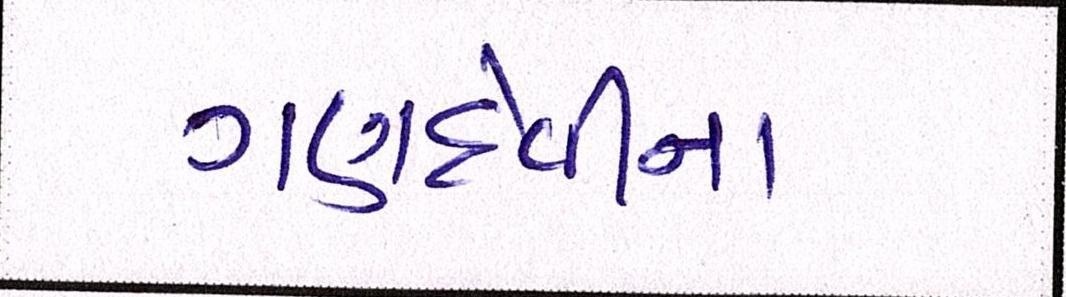 |
|
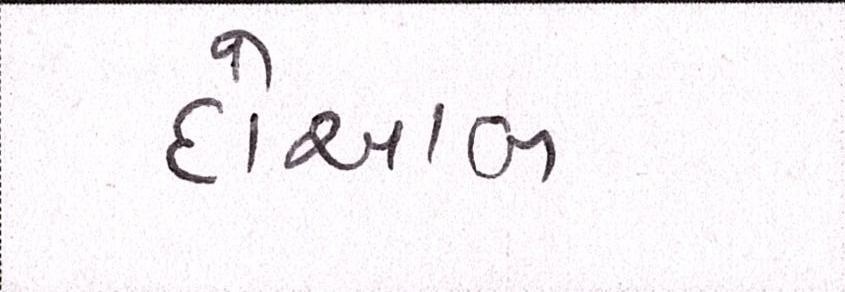 |
|
 |
|
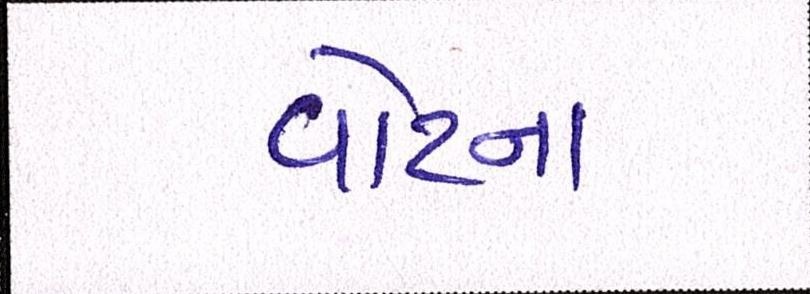 |
|
 |
|
 |
|
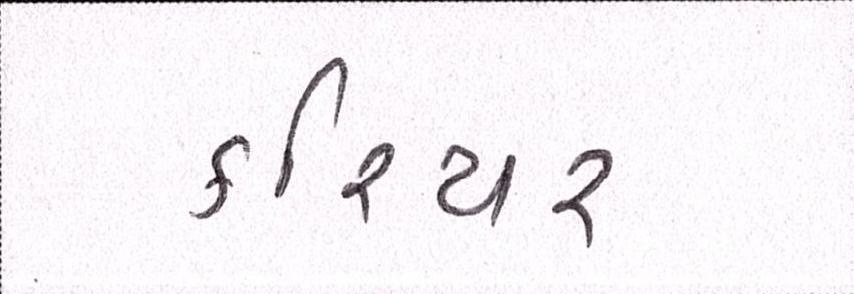 |
|
 |
|
 |
|
 |
|
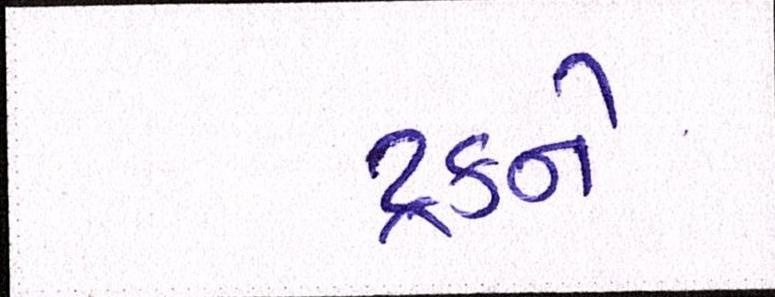 |
|
 |
|
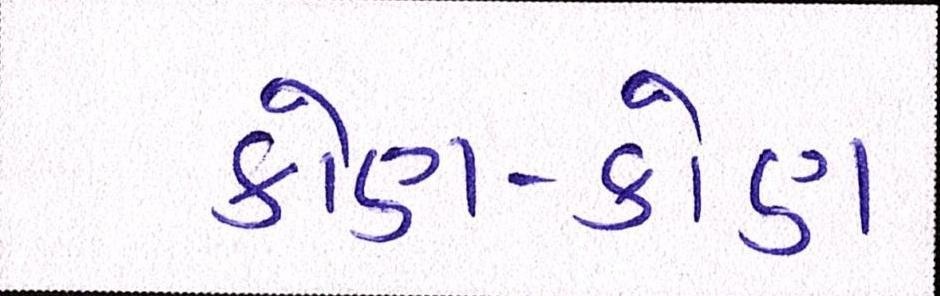 |
|
 |
|
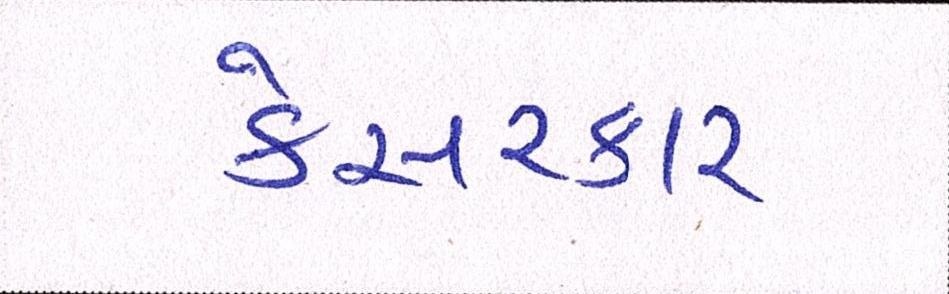 |
|
 |
|
 |
|
 |
|
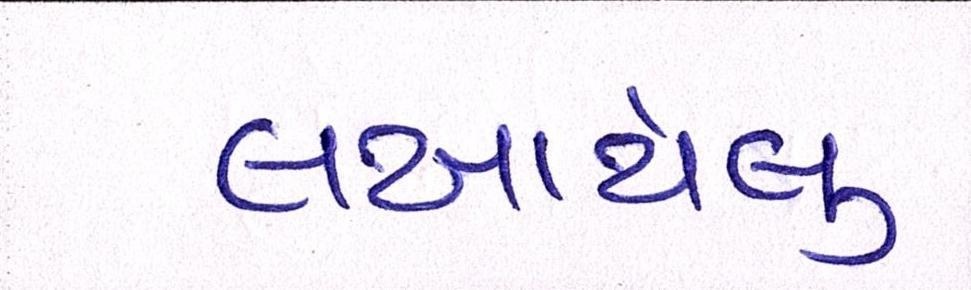 |
|
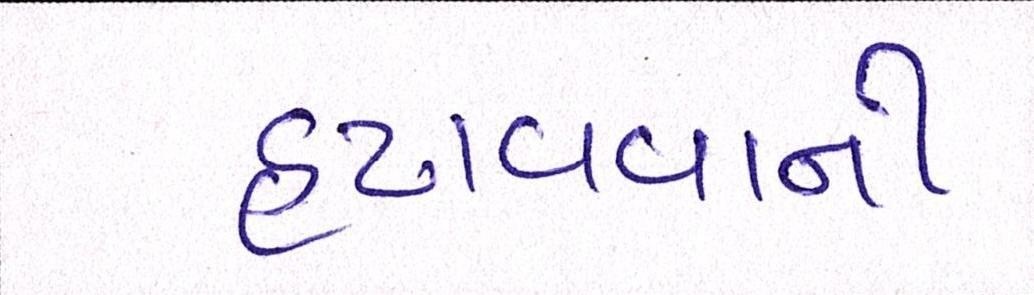 |
|
 |
|
 |
|
 |
|
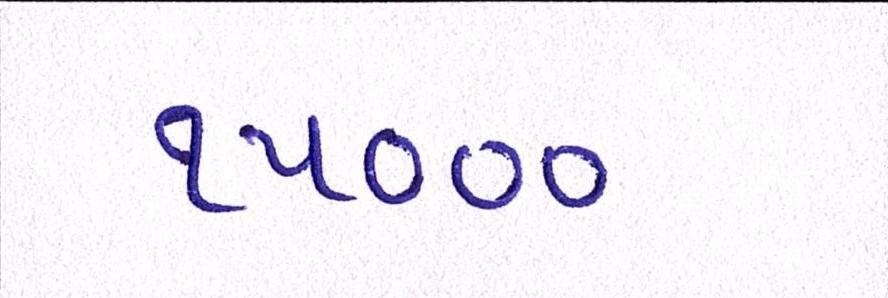 |
|
 |
|
 |
|
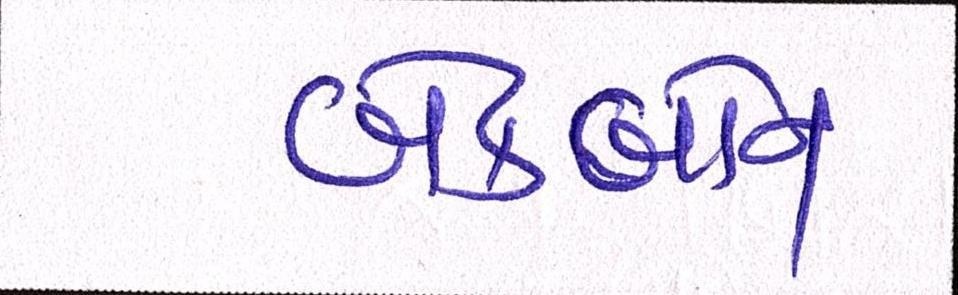 |
|
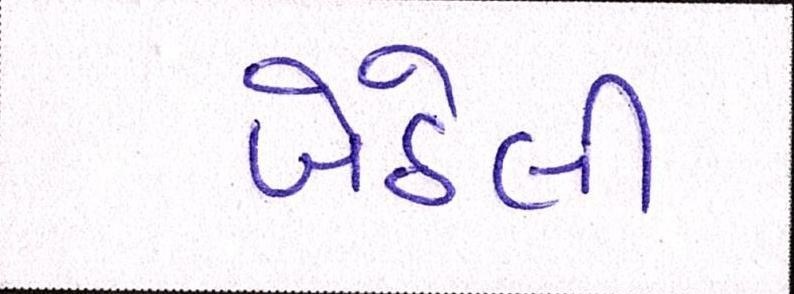 |
|
 |
|
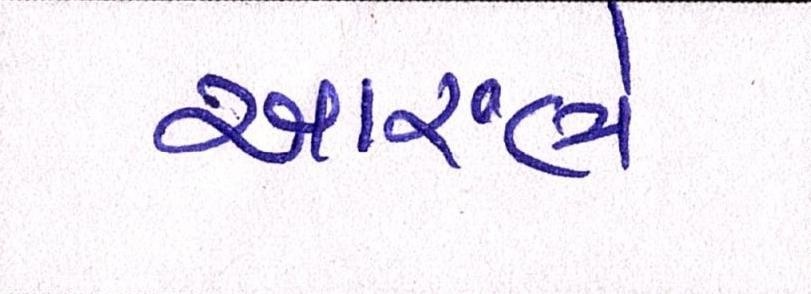 |
|
 |
|
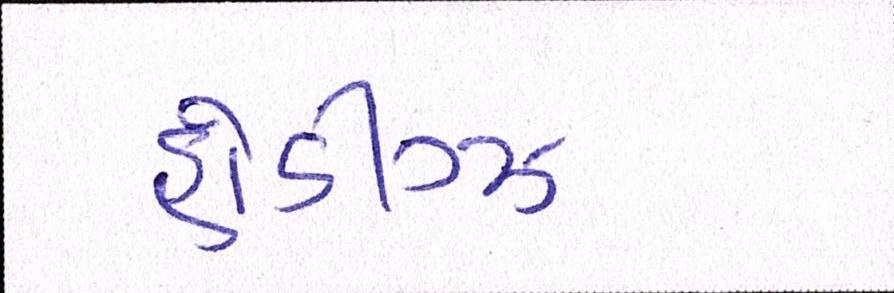 |
|
 |
|
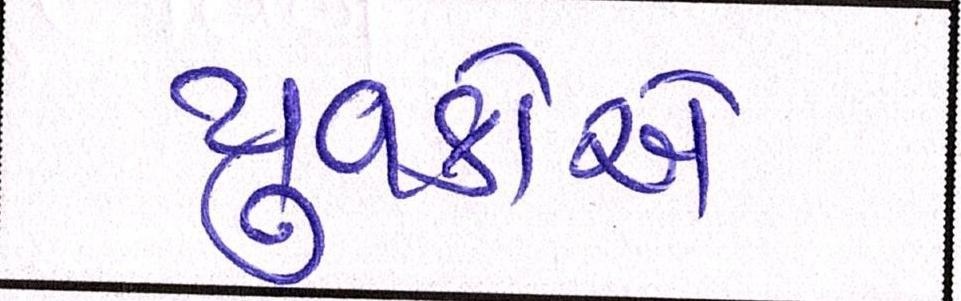 |
|
 |
|
 |
|
 |
|
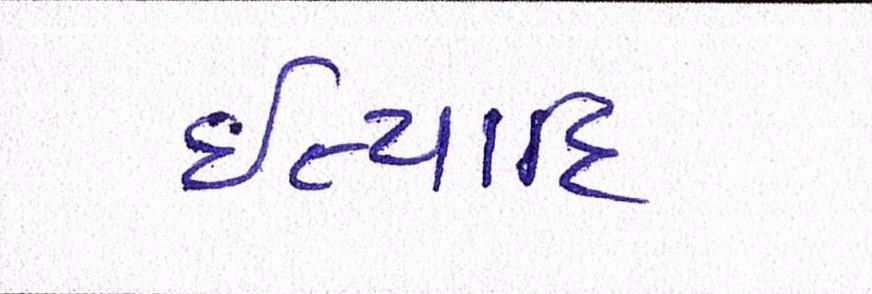 |
|
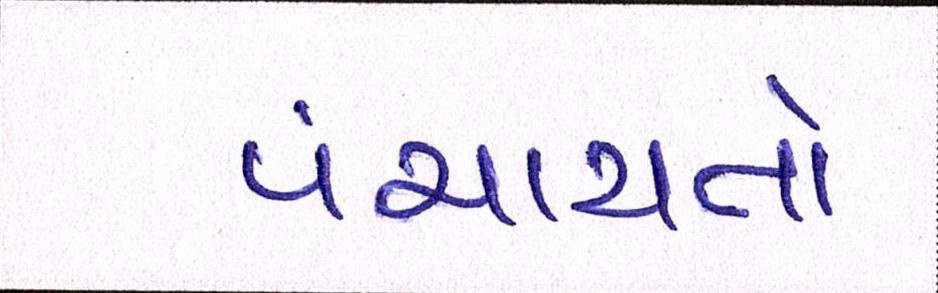 |
|
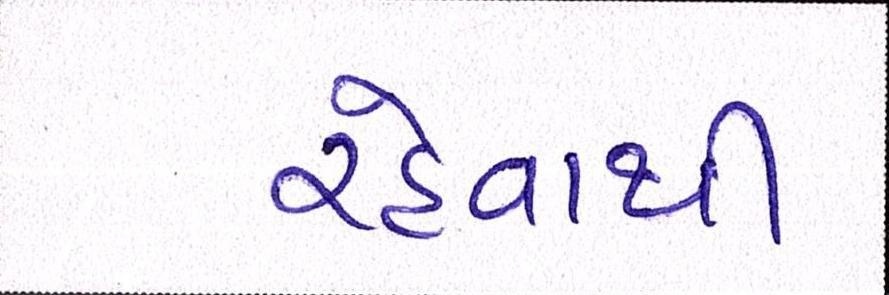 |
|
 |
|
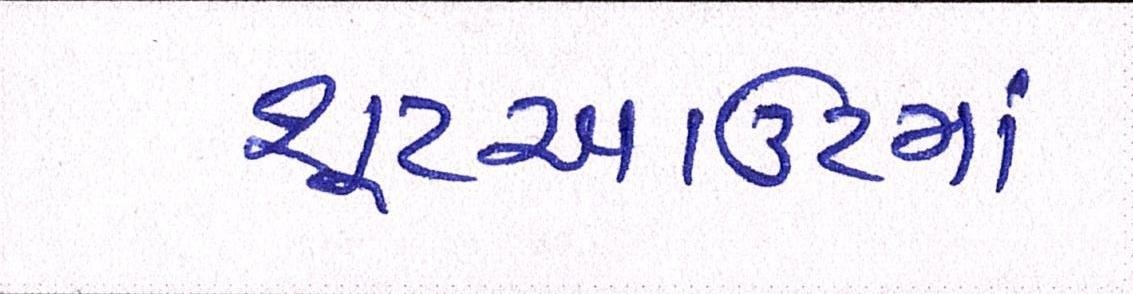 |
|
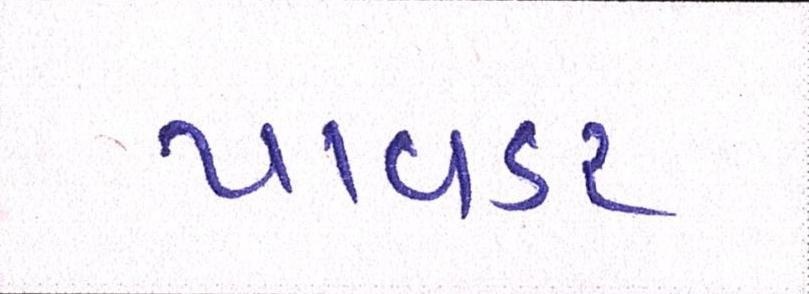 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
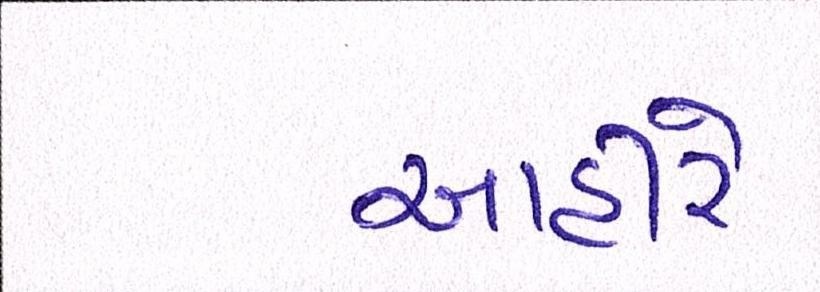 |
|
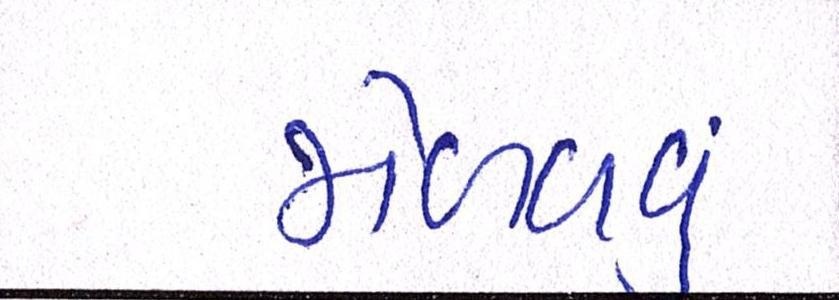 |
|
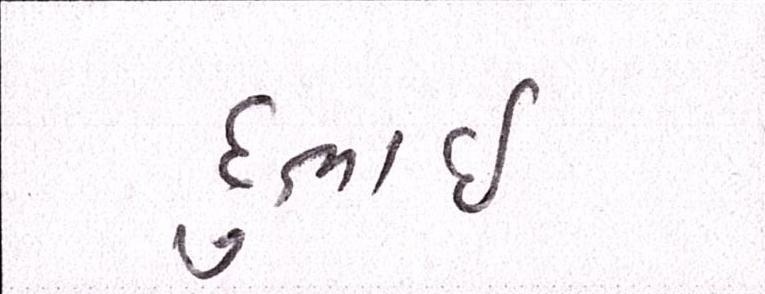 |
|
 |
|
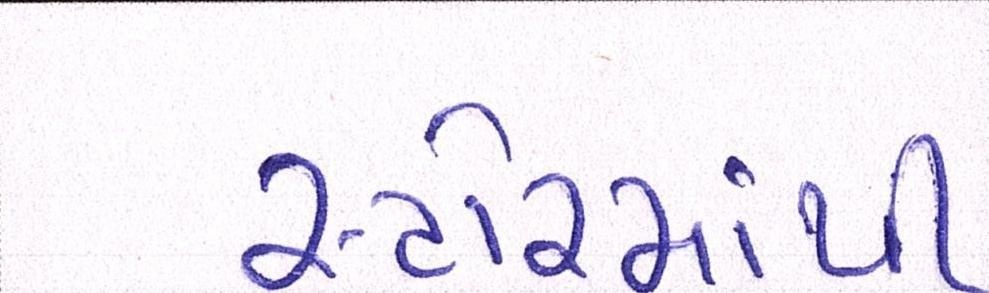 |
|
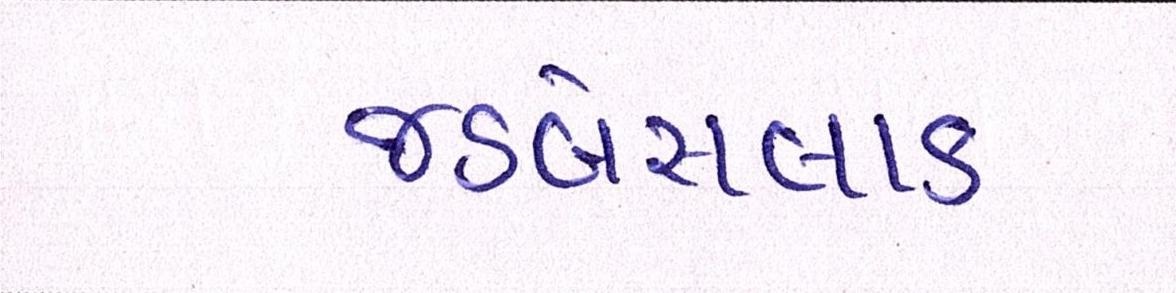 |
|
 |
|
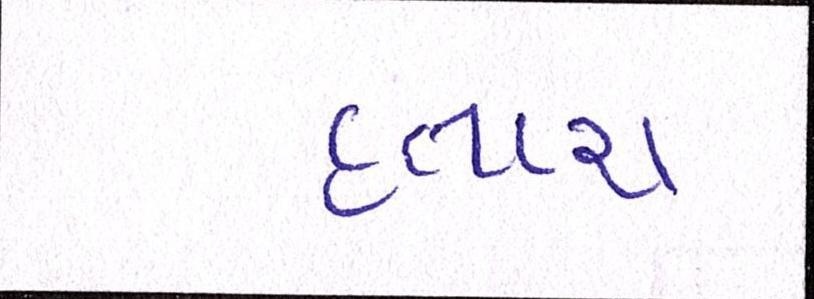 |
|
 |
|
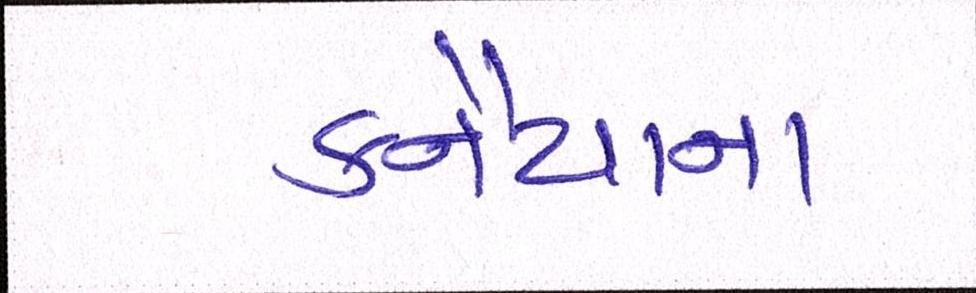 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
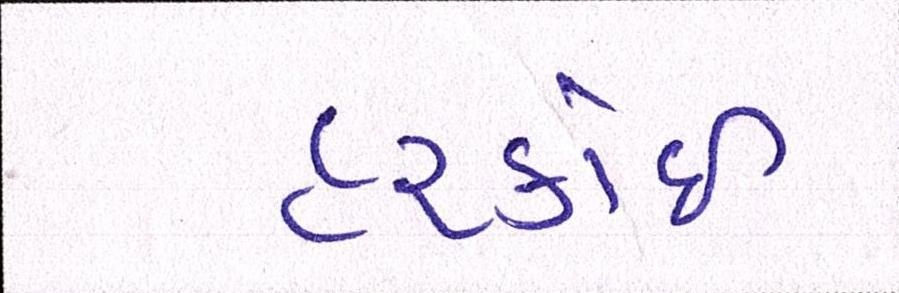 |
|
 |
|
 |
|
 |
Citation
If you use this dataset, please refer these papers
@inproceedings{gongidi2021iiit,
title={iiit-indic-hw-words: A Dataset for Indic Handwritten Text Recognition},
author={Gongidi, Santhoshini and Jawahar, CV},
booktitle={Document Analysis and Recognition--ICDAR 2021: 16th International Conference, Lausanne, Switzerland, September 5--10, 2021, Proceedings, Part IV 16},
pages={444--459},
year={2021},
organization={Springer}}
@inproceedings{dutta2018offline,
title={Offline handwriting recognition on Devanagari using a new benchmark dataset},
author={Dutta, Kartik and Krishnan, Praveen and Mathew, Minesh and Jawahar, CV},
booktitle={2018 13th IAPR international workshop on document analysis systems (DAS)},
pages={25--30},
year={2018},
organization={IEEE}}
@inproceedings{dutta2018towards,
title={Towards spotting and recognition of handwritten words in indic scripts},
author={Dutta, Kartik and Krishnan, Praveen and Mathew, Minesh and Jawahar, CV},
booktitle={2018 16th International Conference on Frontiers in Handwriting Recognition (ICFHR)},
pages={32--37},
year={2018},
organization={IEEE}}
License
This dataset is under the license CC BY 4.0. For more details, please see the data_license.doc file.