IndicSTR12-Tamil
Language
Tamil
Modality
Scene Text
Details Description
This dataset's images have been crawled from Google images using various keyword-based searches to cover all the daily avenues wherein Indic language text can be observed in natural settings. A few of them are mentioned here - wall paintings, railway stations, Signboards, shop/temple/mosque/gurudwara name-boards, advertisement banners, political protests, house plates, etc. Because they have been crawled from a search engine, they come from various sources, offering multiple conditions under which images were captured. Curated images have blurred, non-iconic/iconic text, low-resolution, occlusion, curved text, perspective projections due to non-frontal viewpoints, etc. Words within the images are automatically segmented to get individual word images. Then, we manually create the ground truth transcription of each word. This dataset consists of 2536 word images and their corresponding ground truth transcriptions. We divide this dataset into Training and Test Sets comprising 1902 and 634 word images and their corresponding ground truth transcriptions, respectively. There are 1339 unique Tamil words in the training set.
Training Set:
train.zip contains folder named “images” with 1902 word level images, “train_gt.txt” file containing image name and ground truth transcription separated by “Tab space”, and “list_of_unique_words.txt” contains list of 1339 unique words in the Training set.
Test Set:
test.zip contains folder named “images” with 634 word level images, and “test_gt.txt” containing image name and ground truth text separated by “Tab space”.
Sample Word Level Images from Training Set
| Image | Ground Truth |
|---|---|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
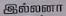 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
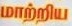 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
Citation
If you use this dataset, please refer these papers
@inproceedings{mathew2017benchmarking,
title={Benchmarking scene text recognition in Devanagari, Telugu and Malayalam},
author={Mathew, Minesh and Jain, Mohit and Jawahar, CV},
booktitle={2017 14th IAPR international conference on document analysis and recognition (ICDAR)},
volume={7},
pages={42--46},
year={2017},
organization={IEEE}
}
@inproceedings{gunna2021transfer,
title={Transfer learning for scene text recognition in Indian languages},
author={Gunna, Sanjana and Saluja, Rohit and Jawahar, CV},
booktitle={International Conference on Document Analysis and Recognition},
pages={182--197},
year={2021},
organization={Springer}
}
@inproceedings{lunia2023indicstr12,
title={IndicSTR12: A Dataset for Indic Scene Text Recognition},
author={Lunia, Harsh and Mondal, Ajoy and Jawahar, CV},
booktitle={International Conference on Document Analysis and Recognition},
pages={233--250},
year={2023},
organization={Springer}
}
License
This dataset is under the license CC BY 4.0. For more details, please see the data_license.doc file.