IIIT-Synthetic-IndicSTR-Hindi
Language
Hindi
Modality
Scene Text
Details Description
The IIIT-Synthetic-IndicSTR-Hindi dataset consists of synthetically created 2M word images along with their corresponding annotations. To create synthetic images, freely available Unicode fonts are used to render synthetic word images. We use ImageMagick, Pango, and Cairo tools to render text onto images. To mimic the typical document images, we generate images whose background is always lighter (higher intensity) than the foreground. Each word is rendered as an image using a random font. Font size, font styling such as bold and italic, foreground and background intensities, kerning, and skew are varied for each image to generate a diverse set of samples. A random one-fourth of the images are smoothed using a Gaussian filter with a standard deviation (𝜎) of 0.5. Finally, all the images are resized to a height of 32 while keeping the original aspect ratio. This dataset is divided into Training, Validation, and Test Sets consisting of 1.5M, 0.5M, and 0.5M word images and their corresponding ground truth transcriptions. There are 3,19,958 Hindi words in the training set.
Training Set:
train.zip contains folder named “images” with 1.5M word level images, “train_gt.txt” containing image name and ground truth text separated by “Tab space” and “vocabulary.txt” contains list of 3,19,958 words in the Training set.
Validation Set:
val.zip contains folder named “images” with 0.5M word level images, and “val_gt.txt” containing image name and ground truth text separated by “Tab space”.
Test Set:
test.zip contains folder named “images” with 0.5M word level images, and “test_gt.txt” containing image name and ground truth text separated by “Tab space”.
Sample Word Level Images from Training Set
| Image | Ground Truth |
|---|---|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
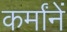 |
|
 |
|
 |
|
 |
|
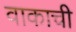 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
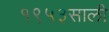 |
Citation
If you use this dataset, please refer these papers
@inproceedings{mathew2017benchmarking,
title={Benchmarking scene text recognition in Devanagari, Telugu and Malayalam},
author={Mathew, Minesh and Jain, Mohit and Jawahar, CV},
booktitle={2017 14th IAPR international conference on document analysis and recognition (ICDAR)},
volume={7},
pages={42--46},
year={2017},
organization={IEEE}
}
@inproceedings{gunna2021transfer,
title={Transfer learning for scene text recognition in Indian languages},
author={Gunna, Sanjana and Saluja, Rohit and Jawahar, CV},
booktitle={International Conference on Document Analysis and Recognition},
pages={182--197},
year={2021},
organization={Springer}
}
@inproceedings{lunia2023indicstr12,
title={IndicSTR12: A Dataset for Indic Scene Text Recognition},
author={Lunia, Harsh and Mondal, Ajoy and Jawahar, CV},
booktitle={International Conference on Document Analysis and Recognition},
pages={233--250},
year={2023},
organization={Springer}
}