Mozhi-Hindi
Language
Hindi
Modality
Printed
Details Description
We randomly crop word images from 1000 document page images to create the Mozhi-Hindi dataset. The pages are taken from multiple books and scanned using a flatbed scanner. The pages are scanned in 600 DPI. We manually annotate ground truth transcriptions of cropped word images. This dataset consists of 1,00,049 word images, and their corresponding ground truth transcriptions. We divide this dataset into Training, Validation, and Test Sets consisting of 79,762, 10,114 and 10,173 word images and their corresponding ground truth transcriptions. There are 11,197 unique Hindi words in the training set.
Training Set:
train.zip contains folder named “images” with 79,762 word level images, “train_gt.txt” file containing image name and ground truth transcription separated by “Tab space”, and “vocabulary.txt” contains list of 11,197 unique words in the Training set.
Validation Set:
val.zip contains folder named “images” with 10,114 word level images, and “val_gt.txt” containing image name and ground truth text separated by “Tab space”.
Test Set:
test.zip contains folder named “images” with 10,173 level images, and “test_gt.txt” containing image name and ground truth text separated by “Tab space”.
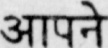
Sample Word Level Images from Training Set
| Image | Ground Truth |
|---|---|
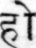 |
|
 |
|
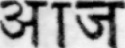 |
|
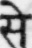 |
|
 |
|
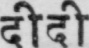 |
|
 |
|
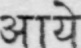 |
|
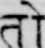 |
|
 |
|
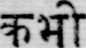 |
|
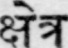 |
|
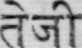 |
|
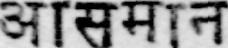 |
|
 |
|
 |
|
 |
|
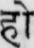 |
|
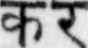 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
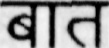 |
|
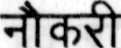 |
|
 |
|
 |
|
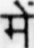 |
|
 |
|
 |
|
 |
|
 |
|
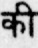 |
|
 |
|
 |
|
 |
|
 |
|
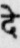 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
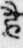 |
|
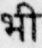 |
|
 |
|
 |
|
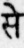 |
|
 |
|
 |
|
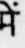 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
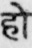 |
|
 |
|
 |
|
 |
|
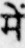 |
|
 |
|
 |
|
 |
|
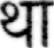 |
|
 |
|
 |
|
 |
|
 |
|
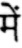 |
|
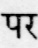 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
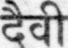 |
|
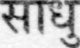 |
|
 |
|
 |
|
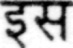 |
|
 |
|
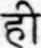 |
|
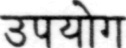 |
|
 |
|
 |
|
 |
|
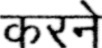 |
|
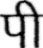 |
|
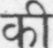 |
|
 |
License
This dataset is under the license CC BY 4.0. For more details, please see the data_license.doc file.