Specific Challenge Tasks
For the challenge, we focus on the following tasks.
In this task, participant methods are required to detect handwritten words across multiple scripts. The input includes document images with handwritten text in various languages, and detection must be performed at the word level. Following figure shows the proposed task.
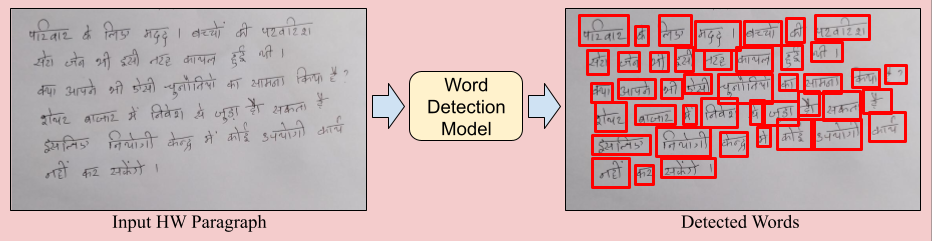
The F-score is the metric employed to rank participants’ methods. It combines recall and precision by comparing the detected word bounding boxes to the ground truth. A detection is deemed correct (true positive) if its bounding box overlaps with the ground truth box by more than 50% (intersection over union).
The primary objective is to develop a robust algorithm that can accurately recognize entire pages while preserving the reading order. Participants may choose to approach this task with word or line level segmentation, applying techniques that improve recognition through finer granularity. The competition also encourages submissions from those who opt not to use segmentation. If segmentation-free approaches achieve results comparable to the highest scores attained with segmentation, they will be recognized as exceptional. Following figure explains the proposed task.
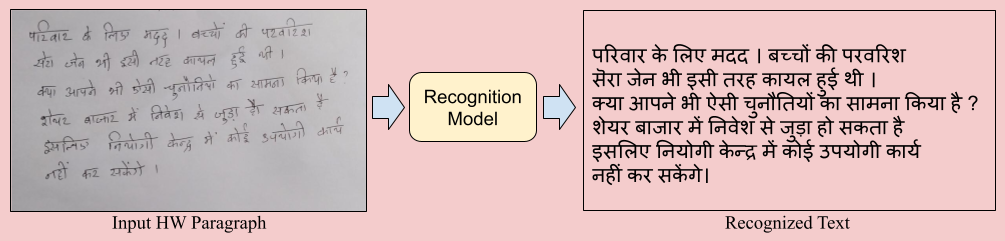
We use two famous evaluation metrics, Character Error Rate (CER) and Word Error Rate (WER), to evaluate the performance of the submitted methods. Error Rate (ER) is defined as $${ER = \frac{(S + D + I)}{N}, (1)}$$ where \(S\) indicates the number of substitutions, \(D\) indicates the number of deletions, \(I\) indicates the number of insertions, and \(N\) number of instances in reference text. In the case of CER, Eq. 1 operates on character level, and in the case of WER, Eq. 1 operates on word level.