Dataset
For recognition task, we collect handwritten pages of four languages, English, Hindi, Bengali, and Telugu, from native writers all over India. We created a web-based online data collection tool for collecting handwritten pages corresponding to the given text paragraphs from native writers. There is no restriction while writing. After writing the page, the writers scan or capture it by mobile and upload handwritten page images into the tool. We collect handwritten page images written by various writers per language. Due to the unconstrained writing, several complexities like significant skew, non-uniform gap between words and lines, and overlapping words. The mobile camera also introduces several other complex issues like orientation, blurring, extra noisy background, cutting of boundary lines, and reflection while capturing pages. A few sample images are shown in Fig.1. We annotate all images manually. For a handwritten page, the ground truth contains bounding boxes, reading order, and text transcription of words in the page. The dataset is divided into a training set and test set per language. We provide ground truths only for the training set.




Fig.1 shows sample handwritten pages in English, Hindi, Telugu, and Bengali languages, respectively.
For the question-answering task on handwritten documents, we gather handwritten pages of population cesus of the United States. Each document provides comprehensive information released up to that date, including details for each individual such as name, address, relationship to the head of the household, color or race, sex, month and year of birth, age at last birthday, marital status, and, if applicable, the number of years married, number of children born of that marriage, and number of children living. It also includes information on places of birth for each individual and their parents, citizenship status, year of immigration (for foreign-born individuals), number of years in the United States, and citizenship status for foreign-born individuals over the age of 21. Additionally, the pages include details about occupation, literacy in English, home ownership, whether the home is a farm, and mortgage status.The pages are manually annotated to include questions and their corresponding answers. Sample pages are shown in Fig. 2.
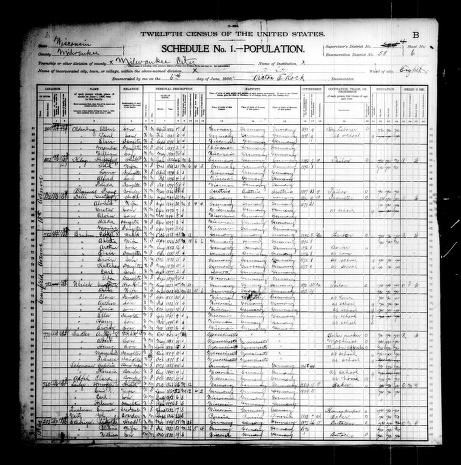
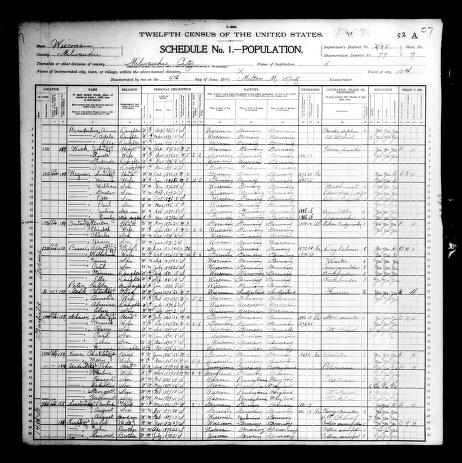


Fig.2 shows sample handwritten pages for question answering task.
Dataset for Task A: Isolated Word Recognition
We have curated a dataset named IHWWR-1.0, which is tailored for text recognition tasks on word images extracted from handwritten documents. This dataset encompasses word images from four distinct languages: English, Hindi, Bengali, and Telugu. It is divided into two subsets: the training and test sets.
Training ses can be downloaded from these links English Hindi Bengali Telugu . Training sets contain word images (in ‘.jpg’ format) and corresponding ground truth transcriptions are available in ‘train.txt. ‘train.txt’ contains the path of training images along with ground truth transcriptions corresponding to each word image, separated by Tab.
Test sets can be downloaded from these links English Hindi Bengali Telugu . Test sets contain an image folder containing word images (in ‘.jpg’ format), and ‘test.txt’ includes the path of test word images.
The output should be saved as ‘script name_result.txt’ (e.g., english_result.txt) which contains names of test word images and corresponding predictions separated by a tab in each line.
Dataset for Task B: Page Level Recognition and Reading
We have compiled a dataset named PLHWTR-1.0, designed explicitly for page level text recognition and reading tasks on handwritten documents. This dataset comprises page level images from four distinct languages: English, Hindi, Bengali, and Telugu. It is divided into two subsets: the training and test sets.
Training sets can be downloaded from these links English Hindi Bengali Telugu . Training sets contain page level images (in ‘.jpg’ format) and corresponding ground truth transcriptions are available in ‘.txt' (e.g., '1.jpg' and '1.txt').
Test sets can be downloaded from these links English Hindi Bengali Telugu . Test sets contain page level images (in ‘.jpg’ format).
There should be one output file corresponding to an image. The output should be saved as ‘image name_result.txt’ (e.g., 12304_result.txt), which contains the predicted text of the complete page image.
Dataset for Task C: Visual Question Answer on Handwritten Documents
We have developed a dataset known as SP-HWVQA-1.0, designed explicitly for performing visual question answering on single-page handwritten documents. This dataset is partitioned into two sets: the training and test sets.
Training set can be downloaded from this link Training Set . It contains 250 images with 750 questions and answers pair. The ground truth is presented as train.json which contains image, question id, question, and corresponding answer.
Test set can be downloaded from this link Test Set . It contains 250 images with 250 questions. The 'test.json' which contains image, question id, and question.
The output should be saved as ‘result.json', which contains image, question id, question, and corresponding answer.
Participants are permitted to utilize supplementary publicly accessible datasets for pre-training purposes. Nonetheless, they are required to specify which datasets were used for pre-training. In Task A and Task B, participants can employ IAM , GNHK , and IHTR-2023 . Conversely, for Task C, participants may utilize DocVQA for pre-training purposes.