Dataset
We use the publicly available FinTabNet [4] datasets for the purpose of this competition. FinTabNet [4] dataset has predefined ground truth labels for table structure recognition, which means that alongside every image, we have bounding boxes for every word/token, digitized text, and row/column identifier. We manually create questions on top of these documents and tag their answers in terms of the actual textual answer by annotating the word/token bounding box(es) used to compute the final answer.
During the training phase, the dataset is divided into two categories - training and validation sets containing 39,999 and 4535 table images respectively. Ground truth corresponding to each table image consists of the following:
- Table Structure Annotation : Each cell is annotated with information about its bounding box, digitised content, and cell spans in terms of start-row, start-column, end-row and end-column indices.
- Difficulty-Wise Sample Questions and Answers : Corresponding to every table image, a few sets of questions along with their answers are annotated in the JSON file. The questions are organised in five categories in the increasing order of difficulty. The questions types primarily include extraction type query, ratio calculations and aggregations across rows and/or columns. Further, answer types are classified as text or numeric. While text answers will be evaluated according to edit-distance based measures, for numeric type answers, absolute difference between the ground-truth and predicted value will also be taken into account. Ideally, to answer all the questions correctly, both syntactic along with semantic understanding of the business document would be required.
- Category 1 : 0 - 25
- Category 2 : 0 - 10
- Category 3 : 0 - 3
- Category 4 : 0 - 7
- Category 5 : 0 - 5

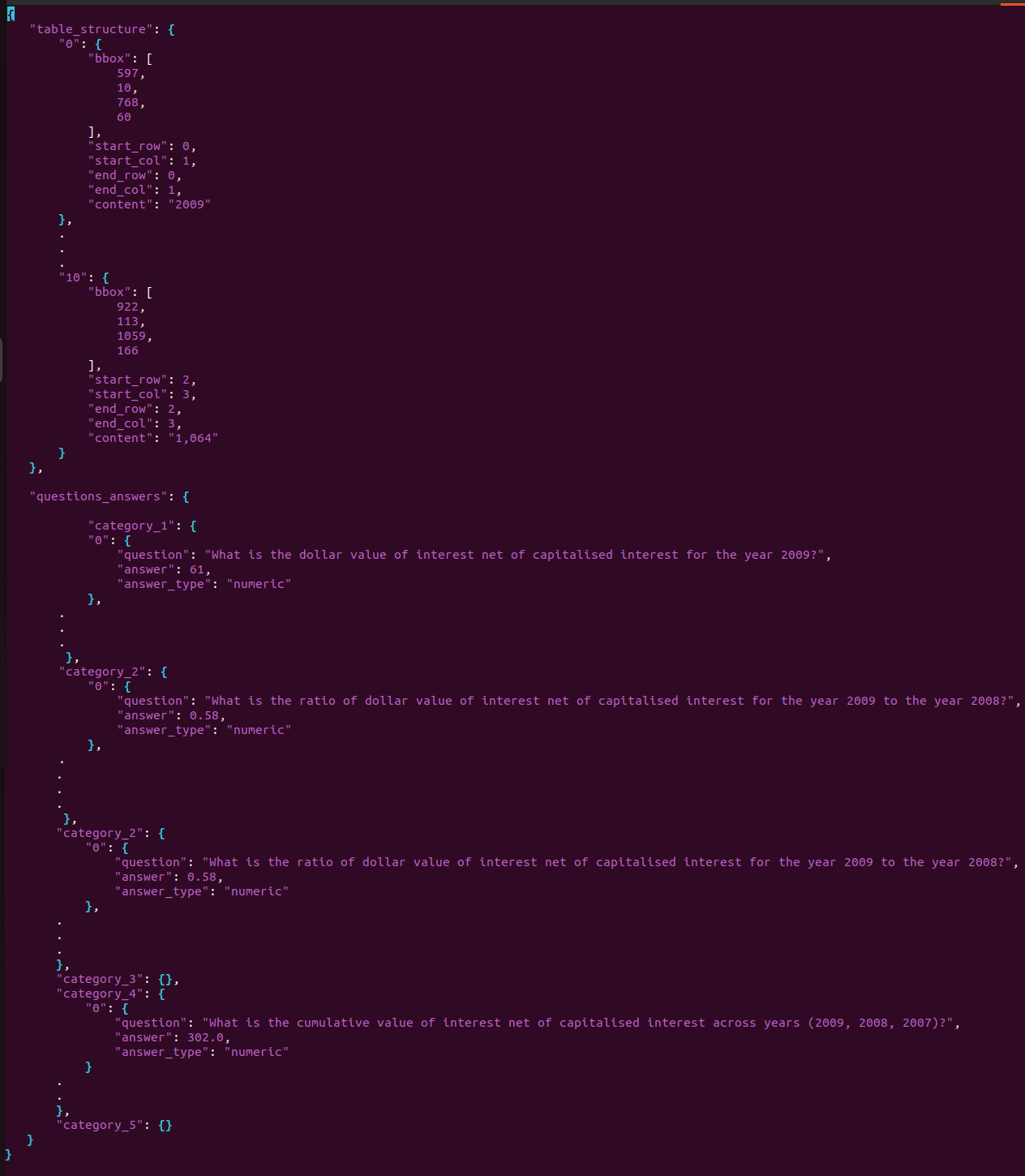
Here, there are 2 primary keys within this JSON :
- Table Structure (table_structure) : Each key within this object is represented by an integer value, cell_id. The object corresponding to this cell_id has information about its bounding box, start_row, start_col, end_row, end_col and content.
- Questions and Answers (questions_answers) : The keys within this object denotes the category of questions (category_1, etc). Further, the object corresponding to each category is again a dictionary with key corresponding to the question_id and value corresponding to the question_object containing the question as the string, its answer and answer type.
Example:

Dataset Statistics (TRAIN) : downloaded
| CATEGORY | Category 1 | Category 2 | Category 3 | Category 4 | Category 5 |
|---|---|---|---|---|---|
| NUMERIC | 632037 | 137395 | 107712 | 187844 | 132370 |
| TEXT | 56807 | 0 | 0 | 0 | 0 |
Total Images : 39999
Total Questions : 1254165
Dataset Statistics (VALIDATION) : downloaded
| CATEGORY | Category 1 | Category 2 | Category 3 | Category 4 | Category 5 |
|---|---|---|---|---|---|
| NUMERIC | 69458 | 15396 | 12471 | 21696 | 15630 |
| TEXT | 6814 | 0 | 0 | 0 | 0 |
Total Images : 4535
Total Questions : 141465
Dataset Statistics (Test) : downloaded
| CATEGORY | Category 1 | Category 2 | Category 3 | Category 4 | Category 5 |
|---|---|---|---|---|---|
| NUMERIC | 68439 | 14705 | 11863 | 20609 | 14245 |
| TEXT | 5964 | 0 | 0 | 0 | 0 |
Total Images : 4361
Total Questions : 135825