Specific Challenge Tasks
For the challenge, we propose following three main tasks (see Fig. 1).
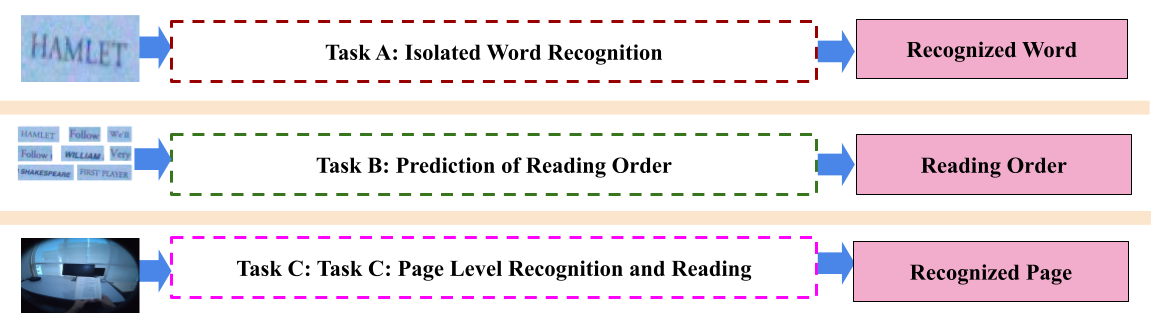
Task A: Isolated Word Recognition in Low Resolution - Task A focuses on designing robust algorithms for isolated word recognition. The primary objective is to create algorithms that accurately recognize each word within a provided set of word images.
Task B: Prediction of Reading Order - This task aims to develop robust algorithms for predicting the reading order (i.e., sequence of words on a page) of word level images extracted from a page.
Task C: Page Level Recognition and Reading - The main goal is to develop a robust algorithm to recognize entire pages while preserving the correct reading order.
Participants can choose their approach for the task, whether it involves automatically cropping the document region from the complete image. If participants use an algorithm for document region cropping, they should include details about this algorithm and their recognition algorithms.
Additionally, participants can approach the task with word or line level segmentation, using techniques that improve recognition through finer granularity. The competition is open to submissions from those who opt not to use segmentation (word or line level). If the performance without segmentation is comparable to the best scores achieved with segmentation, such submissions will be acknowledged as exceptional.
Evaluation Metrics
Task A: Isolated Word Recognition in Low Resolution:
We use two famous evaluation metrics, Character Recognition Rate (\(CRR\)) (alternatively Character Error Rate, \(CER\)) and Word Recognition Rate (\(WRR\)) (alternatively Word Error Rate, \(WER\)), to evaluate the performance of the submitted word level recognizers. Error Rate (\(ER\)) is defined as
$$ { ER= \frac{S+D+I}{N} (1) } $$
Where \(S\) indicates number of substitutions, \(D\) indicates number of deletions, \(I\) indicates number of insertions and \(N\) number of instances in reference text. In case of \(CER\), Eq. (1) operates on character level and in case of \(WER\), Eq. (1) operates on word level. Recognition Rate (\(RR\)) is defined as
$$ { RR = 1-ER (2) } $$
In the case of \(CRR\), Eq. (2) operates on character level, and in the case of \(WRR\), Eq. (2) works on word level.
Task B: Prediction of Reading Order: We use an average page level BLEU score for the evaluation of the reading order prediction task. BLEU [2] is widely used in sequence generation tasks. Since reading order prediction is a sequence-to-sequence mapping, it is natural to evaluate the performance of an algorithm for reading order prediction with BLEU scores. BLEU scores measure the n-gram overlaps between the hypothesis and reference. We define the average page level BLEU score for this task. The page level BLEU refers to the micro-average precision of n-gram overlaps within a paragraph.
Task C: Page Level Recognition:
We average \(CRR\) and \(WRR\), defined in Eq. (2), over all pages in the test set and define new measure average page level \(CRR\) (\(PCRR\)) and average page level \(WRR\) (\(PWRR\)).
$$ { PCRR = \frac{1}{L} \sum_{i=1}^{L} CRR(i), \label{eqn_cr} (3) } $$
and
$$ { PWRR = \frac{1}{L} \sum_{i=1}^{L} WRR(i), \label{eqn_wr} (4) } $$
where \(CRR(i)\) and \(WRR(i)\) are \(CRR\) and \(WRR\) of \(i^{th}\) page in the test set.